返回首页
祖国网帐号登录
没有帐号?
注册
新闻热线 01063878399
热搜
祖国时政
财经报道
文化中国
微信
新浪
移动端
网站首页
新闻资讯
祖国时政
财经报道
文化中国
中国记忆
国际瞭望
国家安全
法治中国
关注民生
>
新闻资讯>
正文
俞栋:语音识别的困难和四项前沿研究
2017-05-27 23:46
来源:
祖国网
5 月 27 日,由机器之心主办、为期两天的全球机器智能峰会(GMIS 2017)在北京 898 创新空间顺利开幕。中国科学院自动化研究所复杂系统管理与控制国家重点实验室主任王飞跃为本次大会做了开幕式致辞,他表示:「如今人工智能非常热,有人说再过几年人类甚至不如鞋底聪明,50% 甚至 70%工作被人工智能取代。」王飞跃对此表示很震惊,但并不认同,他又说:「情况是,再过几年,人类 90% 的工作由人工智能提供,就像今天我们大部分工作是由机器提供的一样。我们的工作就是尽快让我们的鞋底也像人一样聪明,而不是鞋底比我们聪明,并希望机器之心主办的这次全球机器智能峰会让我们知道人工智能会提供一个更美好的未来。」。大会第一天重要嘉宾「LSTM 之父」Jürgen Schmidhuber、Citadel 首席人工智能官邓力、腾讯 AI Lab 副主任俞栋、英特尔 AIPG 数据科学部主任、GE Transportation Digital Solutions CTO Wesly Mukai 等知名人工智能专家参与峰会,并在主题演讲、圆桌论坛等互动形式下,从科学家、企业家、技术专家的视角,解读人工智能的未来发展。
俞栋在 GMIS 2017 现场发表演讲
上午,腾讯 AI Lab 副主任、西雅图人工智能研究室负责人俞栋发表了主题为《语音识别领域的前沿研究(Frontier Research of Speech Recognition)》的演讲,探讨分享了语音识别领域的 4 个前沿问题。俞栋是语音识别和深度学习领域的着名专家。他于 1998 年加入微软公司,此前任微软研究院首席研究员,兼任浙江大学兼职教授和中科大客座教授。迄今为止,他已经出版了两本专着,发表了 160 多篇论文,是 60 余项专利的发明人及深度学习开源软件 CNTK 的发起人和主要作者之一。俞栋曾获 2013 年 IEEE 信号处理协会最佳论文奖。现担任 IEEE 语音语言处理专业委员会委员,之前他也曾担任 IEEE/ACM 音频、语音及语言处理汇刊、IEEE 信号处理杂志等期刊的编委。
以下是俞栋演讲的主要内容:
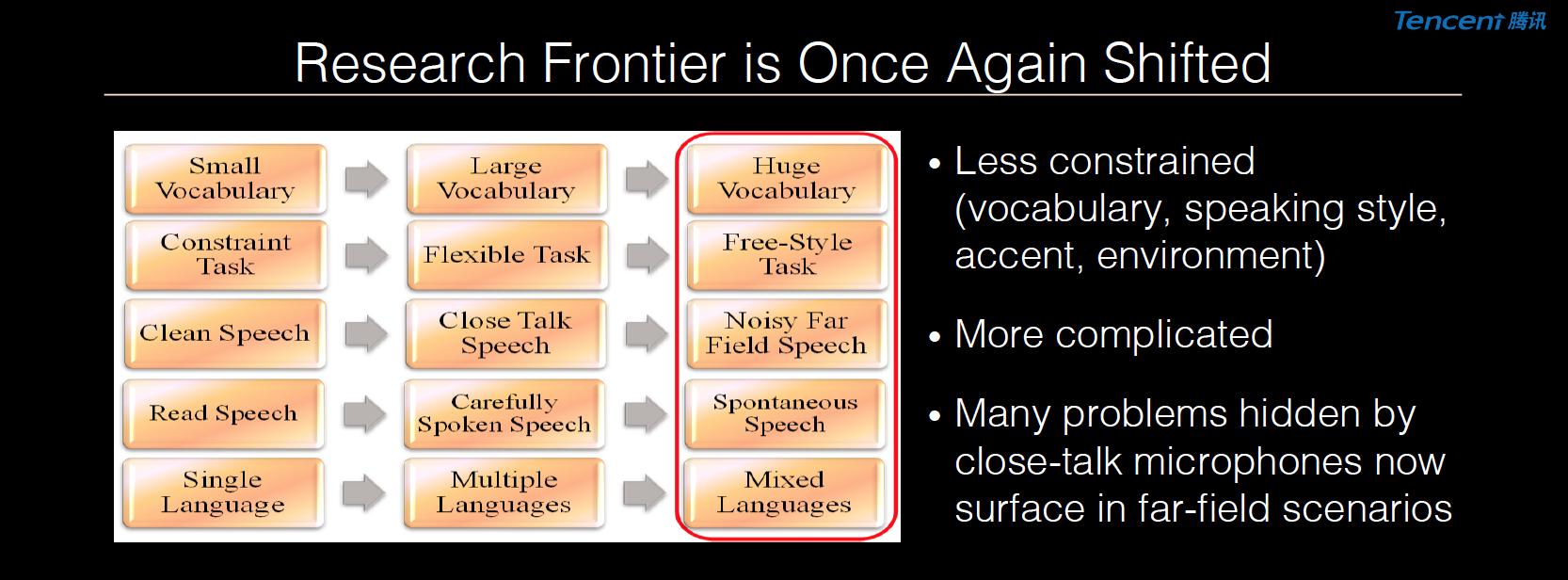
语音识别是一个有着悠久历史的研究领域。在过去的几十年里,研究人员从最简单的小词汇量阅读语音识别问题 Read Speech 开始,逐渐走向更加复杂的 Broadcast Speech 和 Conversational Speech语音识别问题。如今,即便是在以前认为非常难的自由对话这样形式的语音识别问题上,机器也已经达到甚至超过人的识别水准。但是我们要看到,虽然取得了这些进展,但是离真正的人与机器的自由交流还有一定差距,这也就是为什么语音识别的研究前沿又推进了一步。
如今研究的问题越来越没有环境、说话风格、口音、词汇等限定(不像以前有非常多的限制),同时这也增加了语音识别的难度,研究的前沿也从近场麦克风转向远场麦克风,两者的区别在于,在远场情况下,当人的声音传达到麦克风时,声音衰减很厉害。所以以前在近场麦克风很难见到的一些困难,在远场麦克风就变得很明显。如果不解决这些问题,用户在很多的应用场合仍然会觉得语音识别效果欠佳。
所以今天在这样的背景下,我介绍一下最近在语音识别当中的一些前沿的研究方向。
研究方向一:更有效的序列到序列直接转换的模型
语音识别实际上是把语音信号的序列转化为文字或词的序列,所以很多人认为要解决这个问题,找到一个行之有效、序列到序列的转换模型就可以了。
从前的绝大部分研究是通过对问题做假设,然后据此在语音信号序列到词信号之间生成若干个组件,并逐步地转换以生成词的序列。在这些假设中间有许多假设,在某些特定场合它是合理的,但是在很多真实的场景下,它又是有问题的。这种模型实质上是说,如果我们去掉可能存在问题的假设,然后借助数据驱动,就有可能找到更好的方法,使序列转换更准确。
这样做另外一个好处是整个的训练也可以变短。
更有效的序列到序列直接转换的模型目前来讲主要有两个方向:方向一:CTC模型。
CTC模型十分适合语音识别这样的问题,因为它所要求得输出序列长度比输入序列长度要短很多。CTC模型还有一个优势,传统的深度神经网络与混合模型一般来说建模量非常小,但是在CTC模型里面你可以相对自由地选择建模单元,而且在某些场景下建模单元越长、越大,你的识别效果反而会越好。
最近谷歌有一项研究从YouTube上采用几十万小时甚至上百万小时的训练数据量。CTC的模型可以不依赖额外的语言模型就能做到识别率超过传统模型。但由于训练稳定性差,CTC模型相对于传统模型仍然更难训练。
更有效的序列到序列直接转换的模型的第二个方向是:Attention 模型
Attention 模型首先把输入序列、语音信号序列,转换成一个中间层的序列表达,在这个中间层序列表达上面,能够提供足够的信息,然后就可以基于这个信息有一个专门的、基于递归神经网络的生成模型,这个方法在机器翻译里面现在成为了主流方案,但是在语音识别里面它还是一个非常不成熟的技术,它有几个问题在里面。
问题1:只适合短语的识别,对长的句子效果比较差。
问题2:在做语音识别的时候,它的效果是相对来说非常不稳定的。
那么如何解决这些问题?目前最佳的解决方案就是把 CTC 与 Attention 结合起来,这主要是因为CTC有持续信息,可根据后面的语音信号生成词,这有助于 Attention生成更好的表达。两者结合的最终结果既比CTC、Attention各自训练效果更好,所以是一个 1+1 大于 2 的结果。
但是,即便把 CTC 与 Attention 两种模型结合起来,其效果比传统混合模型相比,依然没有太多长进。所以我们仍然需要解决一些问题。
问题一:在这样的架构下面,有没有更好的一些模型结构,或者是训练准则,能够比现有的CTC或者Attention模型更好。
问题二:当拥有的数据较少时,有没有办法建造一个结构,使得语言模型和声学模型紧密结合在一起。
问题三:如何利用各种语料的数据,整合起来训练一个更好的序列到序列转换模型。
研究方向二:鸡尾酒会问题
人在鸡尾酒会这样非常嘈杂的环境中能够把注意力集中在某一个人的声音上,屏蔽掉周围的说话声或噪音,非常好地听懂其要关注的那个人的说话声音。现在绝大部分的语音识别系统却没有这个能力。这个问题在近场麦克风并不明显,这是因为人声的信噪比非常大,而在语音识别系统上,信噪比下降得很厉害,所以说这个问题变得非常突出,成为了一个非常关键、比较难解决的问题。
Label permutation问题目前有两个较好的解决方案:
方案一:Deep Clustering。
方案二:Permutation invariant Training。
但是目前为止我们所用的一些信息,只用到了单麦克风的输入信息。但是我们知道麦克风阵列可以提供很多的信息,所以一个很重要的问题是如何有效地利用多麦克风信息来继续加强其能力。第二个就是有没有办法能够找到一个更好的分离模型,因为现在大家用的还是LSTM,但是LSTM不见得是最佳模型。第三个问题是我们有没有办法利用其他的信息,能否利用这些信息来进一步提升它的性能。
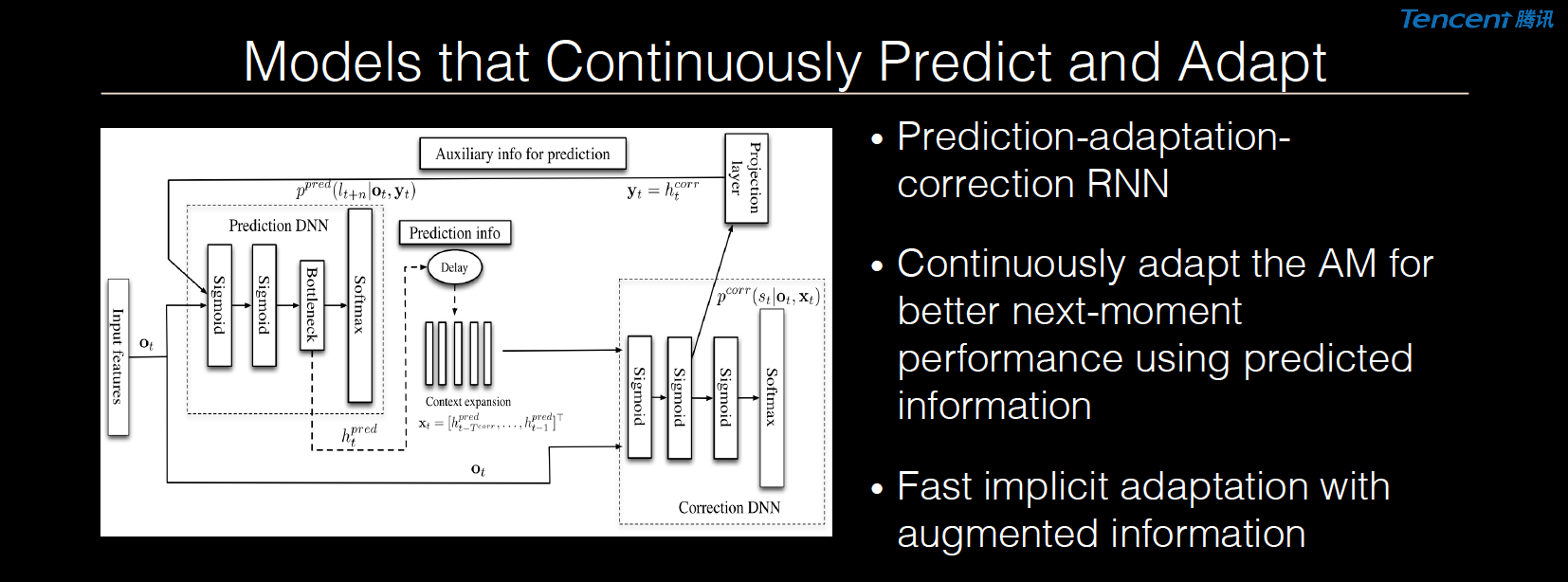
研究方向三:持续预测与适应的模型
第三个大家关注的热点是能否建造一个持续做预测系统。我们之前做了一个模型,它的好处是能够非常快地工作,根据结果来改进下一个数据的识别结果。目前由于模型比较大,所以性能上很难训练。
所以现在的问题是如何建造一个更好的模型,它能够持续地做识别。它需要的特点是什么呢?一个是它能够非常快地做Adaptation,使得下一次再做识别的时候,我们有办法把类似信息用更好的方式压缩在模型里面,所以在下一次可以很快做识别。
研究方向四:前后端联合优化
第四个研究前沿有关远场识别以及如何做前端和后端更好的联合优化。传统来讲,前端的信号处理技术一般只用到当前状态下的语音的信号信息。而机器学习方法用到很多的训练器里学到的信息,但是很少用到当前帧的信息,它不进行数据建模,所以我们有没有办法把这两种方法比较好地融合在一起,这是目前很多研究组织发力的一个方向。
另外,我们有没有办法更好地把前端的信号处理跟后端的语音识别引擎做更好的优化。因为前端信号处理有可能丢失信息,且不可在后端恢复。所以我们有没有办法做一个自动的系统,能够比较好地分配这些信息的信号处理,使得前端可以比较少地丢失信息,从而在后端把这些信息更好地利用起来。
(责任编辑:李俊强)
上一篇
下一篇
相关文档
分享到: